안녕하세요.
매일 공부하는 나루입니다. 데이터분석준전문가 자격증을 준비하며 R을 활용해 머신러닝을 배우고 있습니다. 이번 시간은 R을 활용한 딥러닝을 공부하겠습니다.
1. 학습이란?
예를들어 킬로미터 값과 마일값의 데이터를 가지고 있다고 가정하였을 때, 특정 킬로미터값을 주면 해당 마일이 알려주는 인공지공은 컴퓨터한테 공식을 알려주는 것이 아니라, 데이터를 통해 미지수 c를 찾아내는 가정입니다
(ex) 마일 = 킬로미터 * c(c는 상수)
즉 학습은 데이터를 통해 오차를 줄여가는 과정입니다. 학습방법은 우리가 원하는 분류모델을 찾기위해 방정식을 세웁니다
Y = Ax
- 원점을 지나는 직선으로 분류 가능
- 에러를 통해 A라는 파라미터를 결정하기
- 에러함수를 통해 우리가 찾고자 하는 파라미터 값구하기
- 에러와 파라미터와의 관계식 도출 : △A = E / x
- 업데이트할 마라미터 값을 구하기
오차를 줄이기 위해 데이터를 학습시키고, 오차를 줄이기 위해서 데이터가 많이 필요한데 그래서 빅데이터라는 말이 나오는 것입니다. 상기 식은 linear(직선)에 관련된 것입니다. 아름답지 않은 결과를 아릅답게 하는 것이 learning입니다.
2. Non-linear Classfication은 어떻게 해야할까? Neural Networks
상기는 linear 중심이었는데, 실제는 non-linear일 경우가 많은데, 이를 해결할 수 있는 다른 방법이 'Neural Networks'입니다. 이건 실제 뉴런에서 착안이 된거 같은데, 아래 왼편의 생물학적 뉴런을 보시고 우측의 인공지능을 보시면 어떻게 만들어졌는지 확인할 수 있습니다.

계산은 아래와 같은 과정을 통해 출력이 됩니다. 아래를 보시면 Cell body에서 두번의 과정을 거치게 되고요, 입력은 여러개이고 출력은 0과 1 사이 값 y값이 출력되는 것입니다.

ANN(Artificial Neural Networks)입니다. 아래와 같이 인공지능이 만들어지는 과정입니다. 각각의 Input layer(가지고 있는 데이터 [예] 구매력을 가진 딥러닝을 만들고 싶을 때, 나이, 소비지표 등을 입력), 우리가 만들어야 하는 hidden layer를 입력(이건 계속입력해봐야 어떤 것이 좋은지 알 수 있음, 정답 없음)하고 내가 얻고자 하는 값은 output layer(수치는 0과 1로 나옴, activation을 위해 시그모이드 함수 이용: 0과 1사이의 함수로 보여줌)라고 볼 수 있습니다.
그런데 인공지능이 한번에 나오는 것이 아니기 때문에, 컴퓨터 성능도 중요하고 테스트하는데도 시간이 많이 걸린다고 합니다. 절대 쉽게 결과값을 얻어지는게 아닌 것 같습니다. 그만큼 인공지능을 만들기위해 많은 인고의 시간이 투입이 되어야 하네요. 또한, 사양 좋은 인공지능을 결과를 얻을 수 있습니다.

■ 참고사항
- Activation Function (Maxout과 ELU제외하고 모두 잘 쓰이는 편임)
- Activation 함수로 hidden layer로 ReLU와 Leaky ReLU를 많이 사용함
- 예측은 Sigmoid 함수로 사용함
- 여러개 분류는 Softmax 함수를 사용함

- Back Propagation : 정확한 목표값과 신경망이 계산 값의 오차를 통해 아웃풋 레이어부터 뒤로 가중치를 업데이트 하는 것은 back propagation이라함, 기울기가 0이 되면 업데이트가 안 됨
3. 학습을 통해 가중치 W의 값을 구하는 것이 목표
- 오차를 구한다 : 학습 계산을위해, 가중치 초기 값은 랜덤 설정
- 오차가 최소가 된다는 의미: 정확도가 높다는 뜻, 학습, 예측, 분류가 잘 된다는 뜻
- 오차가 최소가 될 때까지 가중치 값 구하기: 입력 데이터를 계속넣어서, 가중치를 업데이트 하기, 오차가 최소가 되었다는 뜻은 학습이 끝났다는 뜻임
4. 오차 구하기(오차가 0에 가까울 수록 좋은 것임)
- 오차 = 데이터에 존재하는 목표 값 - 신경망이 계산한 값
- 오차함수 정의 : Squarred Error 이용
- Squared Error 함수 사용 이유: Greadient Descent(경사하강법) 이용이 쉽고, 계속하고 minia에서 기울기 크기가 작아짐
- 오차가 최소가 되는 점을 찾기 : Gradient Descent 알고리즘(현재위치 - 현재위치에서 기울기)을 사용해서 새로운 w값을 찾을 수 있음, 미분항 값이 0이 될 때까지 계산함

Point! 딥러닝은 예측과 분류를 모두 할 수 있습니다.
5. R로 연습
<예측문제>
- 집값 예측위한 보스톤 집값 데이터 가져오기

- 딥러닝 모델링 : install.packages('neuralnet')

- 모델링 > 결과 값

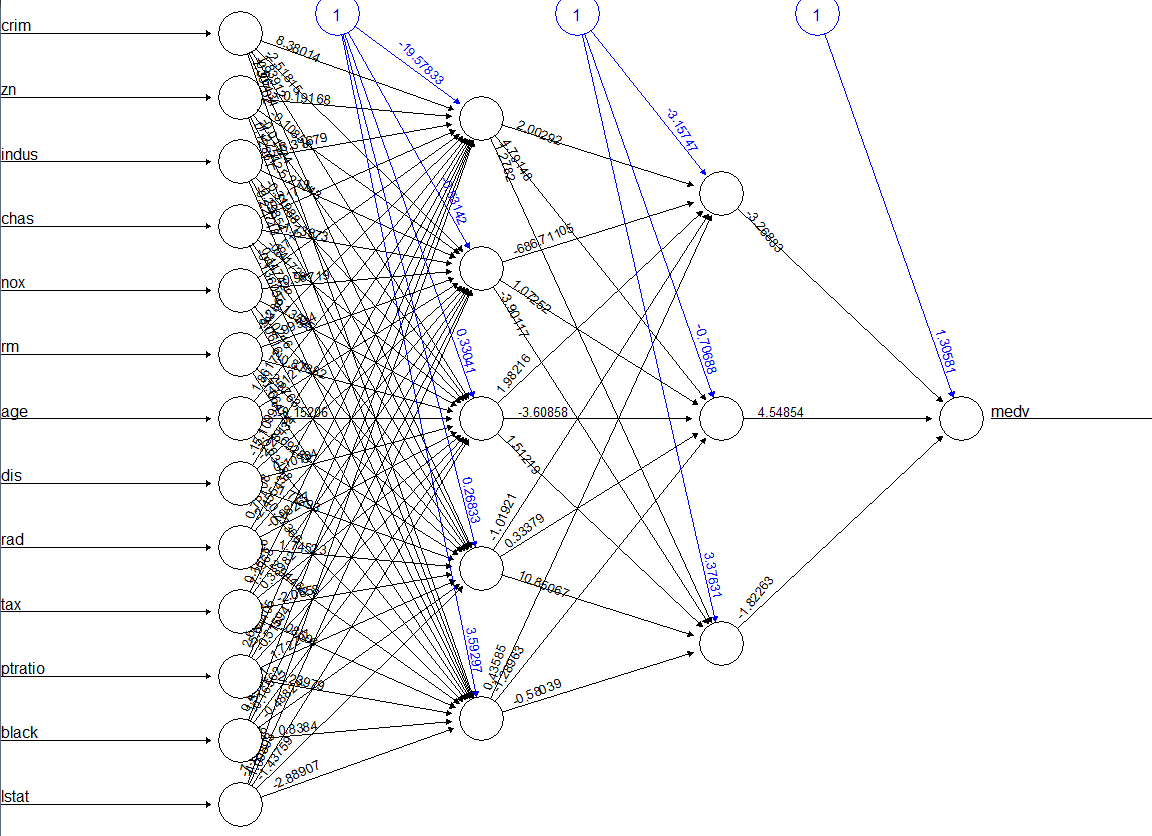
- test_set으로 검토해보기, 예측한 값 살펴보기, List로 저장됨


- 그래프를 확인하면 직선이 아닌 것을 확인할 수 있음


<분류문제>
- 지폐분류 문제

- 모델링

- 0.5 기준으로 반올림, 0과 1의 값으로만 나옴

- confusion matrix 계산
cm = table(test_set$Class, y_pred.round)
- 랜덤 포레스트 random forest => decision tree 개선

- 랜덤 포레스트 모델링(결과는 인공지능이 더 괜찮다는 것으로 파악할 수 있음)

위와 같이 딥러닝 공부했습니다. 무엇보다 실제 분석에 적용할 수 있는 것이 가장 중요할 거 같습니다. 이상입니다.
긴 글 읽어주셔서 감사합니다.
총총
※ 딥러닝에는 미분과 행렬계산이 들어감...!
※ 공부하기에 좋은 참고자료
- 신경망 첫걸음 - 한빛미디어
- Machine learning - Stanford University

'문과생 DT 정복기 > DT 공부하기' 카테고리의 다른 글
| [AI] 멀티모달 인공지능 등장, 생성형 AI를 업무에 접목 (0) | 2023.10.21 |
|---|---|
| [테크] AI·원격의료로 한국형 디지털 헬스 선도 다짐 김영대 신임 서울대병원장 (0) | 2023.04.26 |
| R활용 머신러닝(Machine Learning)_ 연관규칙 분석, apriori / inspect 함수 (0) | 2020.07.11 |
| R활용 머신러닝(Machine Learning)_ Decision Tree, K-means, Hierarchical Clustering (HC) (0) | 2020.07.09 |
| R활용 머신러닝(Machine learning)- KNN, SVM, Guassian RBF Kernel (0) | 2020.07.07 |



